De lock-in-val: Je AI-kennis verdwijnt bij elke providerwisseling
Stel je voor dat je maandenlang met een AI-assistent hebt gewerkt. Je hebt hem geleerd hoe je e-mails schrijft, hoe je bedrijf werkt, welke klanten belangrijk zijn. De assistent kent je voorkeuren, je afkortingen, je manier van werken. Dan komt er een nieuw model op de markt — beter, sneller, goedkoper. Je stapt over. En alles begint opnieuw.
Dat is de realiteit voor de meeste mensen die vandaag met AI werken. Al hun kennis leeft in chatgeschiedenissen. In conversaties die aan een bepaald product gebonden zijn. Nieuw abonnement? Nieuwe provider? Alles weg. Je prompts, je context, je moeizaam opgebouwde voorkeuren — verdwenen als een gewist bestand.
Ik noem dit de lock-in-val. En die treft niet alleen individuen, maar hele bedrijven. Teams die hun proceskennis verstoppen in ChatGPT-threads. Afdelingen die hun beste prompts begraven in Slack-berichten. Leidinggevenden die niet eens weten welke AI-kennis er in hun bedrijf bestaat — omdat het nergens gedocumenteerd is.
Er is een betere manier.
De File-First-aanpak: Je kennis hoort in bestanden, niet in chats
Bij neuroflash zijn we ruim een jaar geleden begonnen ons AI-systeem fundamenteel anders op te bouwen. In plaats van onze kennis in chatgeschiedenissen op te slaan, leggen we alles vast als Markdown-bestanden in mappen. Klinkt simpel? Dat is het ook. En dat is precies het punt.
De structuur ziet er zo uit:
CLAUDE.md— je persoonlijke gebruiksaanwijzing. Wie je bent, hoe je werkt, welke regels gelden. Als de AI dit bestand leest, weet ze meteen met wie ze te maken heeft.skills/— elke workflow is een map met eenSKILL.mden optionele scripts. Blog schrijven? Skill. LinkedIn-post maken? Skill. Factuur controleren? Skill.entities/— mensen, bedrijven, projecten als gestructureerde.md-bestanden. Je CRM in tekstvorm.memory/— wat de AI heeft geleerd over de samenwerking met jou. Correcties, voorkeuren, inzichten.
Dat zijn gewoon tekstbestanden. Geen database. Geen propriëtair formaat. Geen vendor-lock-in. Je kunt ze openen met elke teksteditor, versiebeheren met Git en synchroniseren via Dropbox.
Andrej Karpathy — voormalig AI-chef bij Tesla en een van de meest invloedrijke koppen in het AI-onderzoek — heeft het onlangs kernachtig verwoord: De toekomst behoort aan systemen waarin mensen en AI samen aan bestanden werken. Niet systemen waarin de AI alles in het verborgene doet.
Waarom dit je modelonafhankelijk maakt
Vandaag draait ons systeem op Claude Code van Anthropic. Morgen kan het GPT-5, Gemini 3 of een open-sourcemodel op eigen servers zijn. De overstap? Motor vervangen, bestanden behouden.
Skills blijven. Entities blijven. Memories blijven. Nul migratiekosten.
Dit is geen theoretisch scenario. We hebben het al gedaan. Toen we van het ene model naar het andere zijn overgestapt, duurde het geen 30 minuten. Map kopiëren, configuratie aanpassen, verder werken. Alle kennis — de honderden skills, de duizenden entities, de verzamelde herinneringen — alles was meteen beschikbaar.
Vergelijk dat met de gebruikelijke aanpak: je stapt over van ChatGPT naar Claude en begint bij nul. Geen context. Geen voorkeuren. Geen aangeleerde patronen. Alsof je een nieuwe medewerker aanneemt die nog nooit van je bedrijf heeft gehoord.
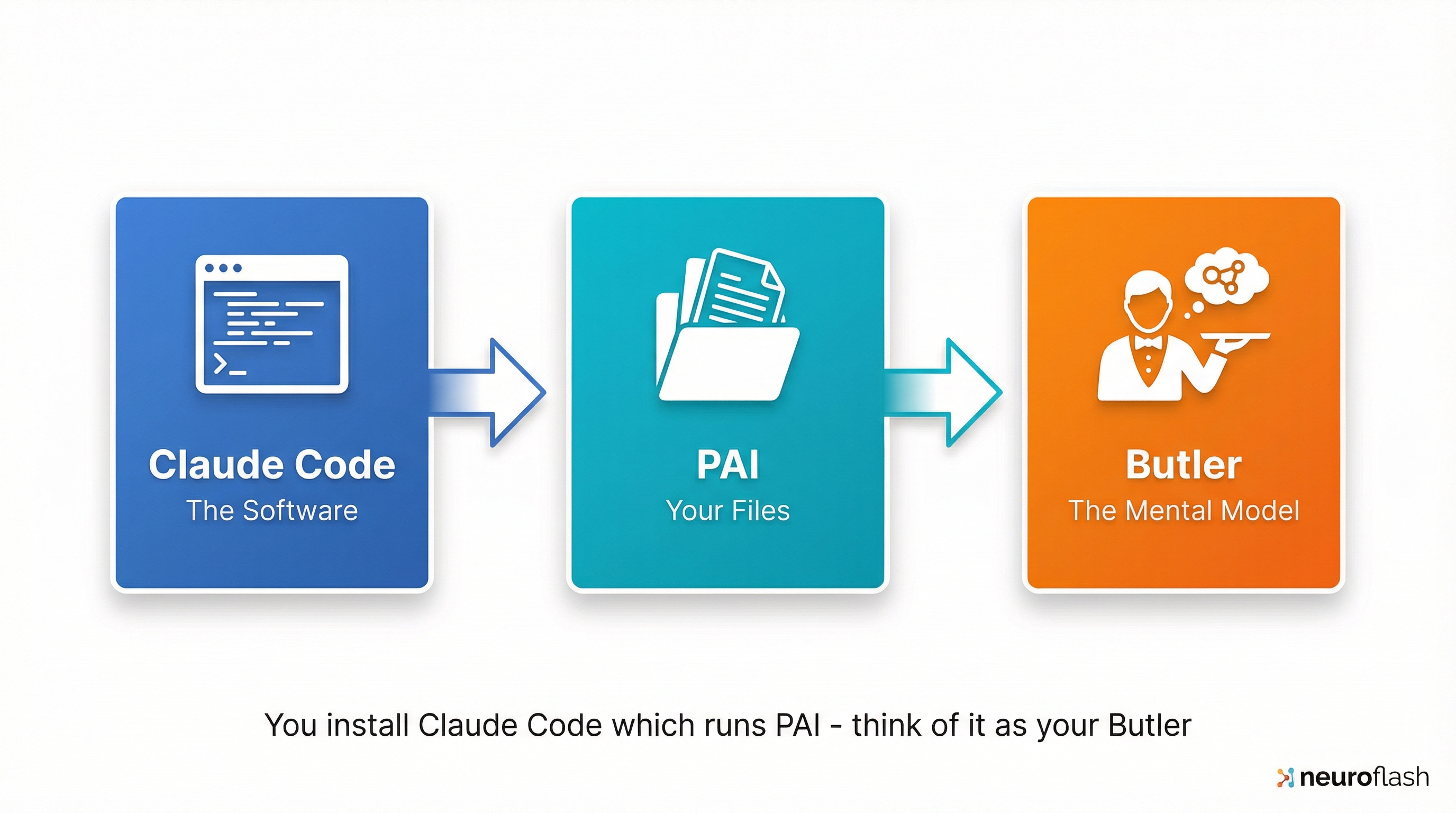
Software (Claude Code), bestanden (PAI) en mentaal model (Butler) horen bij elkaar maar blijven uitwisselbaar — alleen de bestanden zijn blijvend van jou.
Je wordt een digitale tweeling
Hier wordt het pas echt interessant. Als je documenteert hoe je werkt, wie je kent, wat je hebt geleerd en welke processen je volgt — dan maak je een machineleesbare versie van jezelf. Een digitale tweeling van je werk.
Niet in de griezelige bewakingszin. Maar in de praktische: elke AI die je bestanden leest, kan namens jou handelen. Met jouw context. Volgens jouw regels. Ze weet dat je e-mails liever kort houdt, dat je bij blogartikelen altijd een SEO-analyse nodig hebt, dat je op woensdag nooit afspraken voor 10 uur wilt hebben.
Het onderzoek naar digitale tweelingen — oorspronkelijk uit de industriële context (Tao et al., 2017) — beschrijft precies dit principe: een virtuele afbeelding die de toestand en het gedrag van zijn fysieke tegenhanger weerspiegelt. Wij passen dit toe op kenniswerk.
Voor bedrijven is dit nog krachtiger. Als de skills en entities van elk teamlid in een gezamenlijke bibliotheek samenkomen, wordt het bedrijf zelf een digitale tweeling. Nieuwe medewerker? Die erft de collectieve kennis op de eerste dag. Hij kloont het skill-repository, draait de onboarding-skill en is binnen enkele uren productief.
Een SKILL.md-bestand is in wezen een API-specificatie voor een menselijke workflow. Elke voldoende krachtige AI kan het lezen en uitvoeren. Dat is je digitale tweeling in actie.
De leercyclus: Bestanden vergeten niet
Het mooie van dit systeem is de leercyclus. Elke keer dat je de AI corrigeert, kun je die correctie als memory opslaan. Elke keer dat je een nieuw probleem oplost, kun je het als skill documenteren. De bestanden groeien. De tweeling wordt completer.
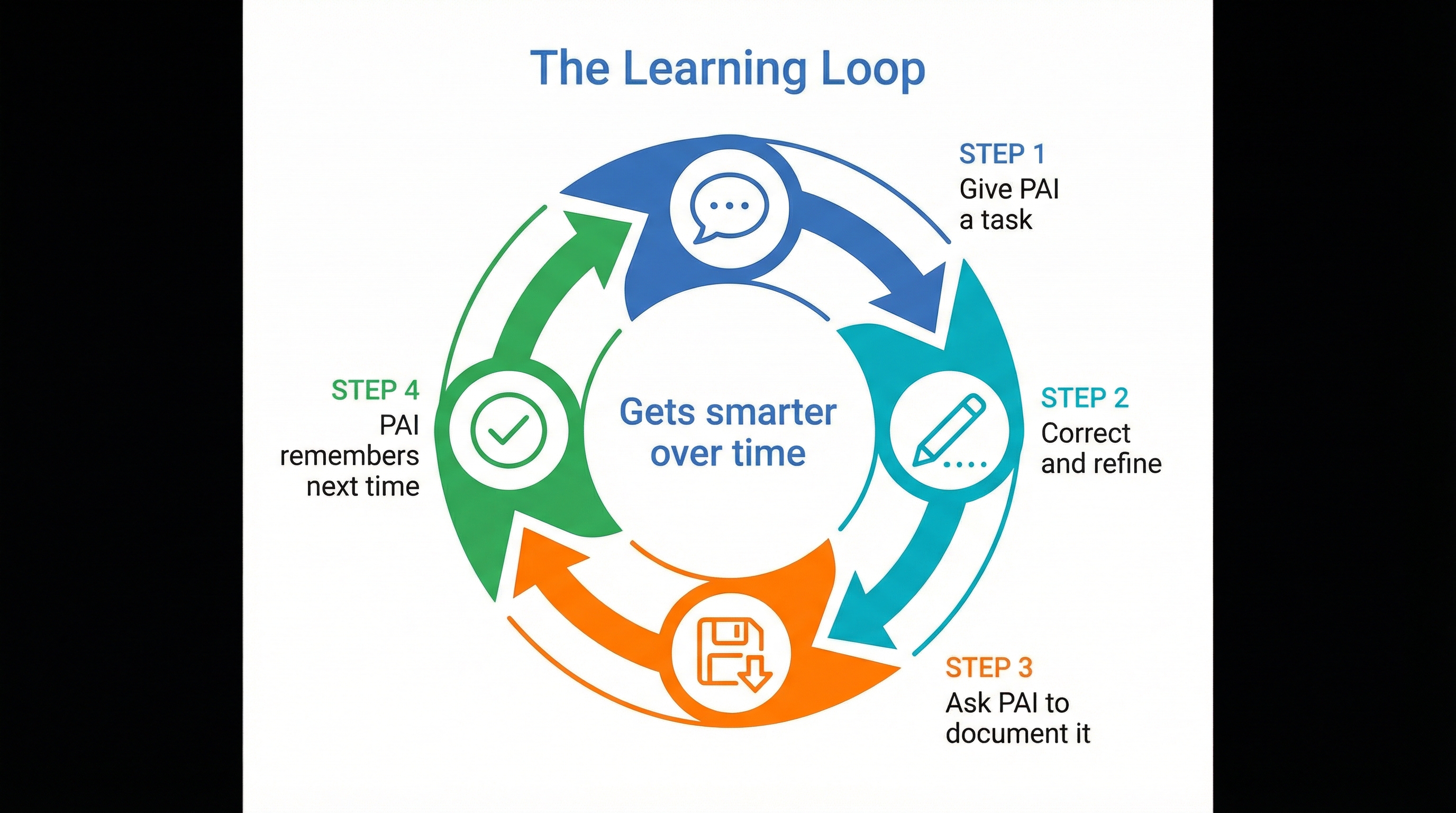
De leercyclus maakt van elke correctie een blijvend memorybestand — anders dan een model dat tussen sessies vergeet, groeit jouw digitale tweeling met elke interactie.
En anders dan een getraind model dat tussen sessies vergeet: Bestanden vergeten niet.
Een voorbeeld uit ons dagelijks werk: vorige week schreef de AI een LinkedIn-post met een bepaalde toon die me niet beviel. Ik heb haar gecorrigeerd, en de correctie werd automatisch opgeslagen in een memory-bestand. Vanaf nu — of ik morgen, volgende week of over drie maanden een LinkedIn-post schrijf — wordt die voorkeur meegenomen. Niet omdat het model “geleerd” heeft, maar omdat het bestand het weet.
Dit principe schaalt. Na maanden van gebruik bevat ons systeem honderden van zulke correcties en inzichten. Elk daarvan is een klein stukje gedocumenteerde kennis dat de digitale tweeling preciezer maakt. En elk daarvan overleeft elke modelwisseling.
Drie praktische voorbeelden
1. Modelwisseling in 30 minuten
Toen we van het ene AI-model naar het andere overstapten, was het proces triviaal: map kopiëren, engine-configuratie aanpassen, klaar. Alle skills, alle entities, alle memories — meteen beschikbaar. Geen retraining, geen prompt-engineering vanaf nul, geen kennisverlies. De nieuwe motor las dezelfde bestanden en kon direct aan de slag.
2. Onboarding op de eerste dag
Als een nieuw teamlid bij ons begint, kloont diegene het gezamenlijke skill-repository. Daar vindt hij gedocumenteerde workflows voor alles: hoe we blogartikelen schrijven, hoe we facturen controleren, hoe we klantgegevens onderhouden. Er is een onboarding-skill die stap voor stap door de inrichting begeleidt. In plaats van wekenlange inwerkperiode is de persoon binnen enkele uren productief — omdat de digitale tweeling van het bedrijf alles uitlegt.
3. Versiebeheer voor processen
Omdat onze skills in Git staan, kunnen we zien hoe processen zich in de loop van de tijd hebben ontwikkeld. We kunnen fouten terugdraaien. We kunnen samenwerken aan verbeteringen, precies zoals ontwikkelaars aan code werken. Een SKILL.md-bestand heeft een Git-history. Een chatgeschiedenis niet.
Veelgestelde vragen
Wat is een digitale tweeling in AI?
Een digitale tweeling is je persoonlijke kennissysteem in bestandsvorm. Het slaat je ervaringen, voorkeuren en werkwijzen op zodat elke AI-agent er toegang toe heeft – ongeacht de aanbieder of het model.
Zijn Markdown-skills modelonafhankelijk?
Ja, Markdown-skills zijn volledig modelonafhankelijk. Omdat ze als gewone tekstbestanden bestaan, kan elk AI-model ze lezen en uitvoeren. Je bent niet gebonden aan een specifieke aanbieder en kunt op elk moment wisselen.
Hoe maak ik mezelf onafhankelijk van een AI-aanbieder?
Sla je kennis op in lokale bestanden in plaats van cloudchats. Gebruik Markdown voor workflows en templates die elk model begrijpt. Zo blijft je opgebouwde kennis bij jou, of je nu Claude, GPT of een ander model gebruikt.
De software is vervangbaar. Je bestanden niet.
Dit is het centrale inzicht dat ik je wil meegeven: Je traint geen AI. Je bouwt een digitale tweeling van hoe je werkt. En elke AI kan deze tweeling bewonen.
Claude Code, Copilot, wat er ook hierna komt — dat is de software. Die is vervangbaar. Je bestanden — de skills, de entities, de memories, de instructies — dat ben jij. Dat is je bedrijf. Dat is het echte intellectuele eigendom.
Niet opgesloten in iemands hoofd. Niet begraven in een propriëtaire tool. In eenvoudige tekstbestanden die iedereen kan lezen, versiebeheren en delen.
Als je morgen wilt beginnen: maak een map aan. Schrijf een CLAUDE.md (of hoe je hem ook wilt noemen) met een beschrijving van jezelf en je werk. Documenteer je eerste workflow als skill. Leg een entity aan voor je belangrijkste project. Dat is misschien 30 minuten werk.
Maar die 30 minuten maken je onafhankelijk. Van elk model. Van elke provider. Van elke hype die morgen in de AI-wereld opduikt en overmorgen weer verdwijnt.
Je digitale tweeling is van jou. Zorg ervoor dat hij in bestanden leeft — niet in andermans chats.
Bronnen & verdere artikelen
- Claude Code — Anthropic Documentatie
- Andrej Karpathy — AI-onderzoek en perspectieven
- Tao et al. (2017): Digital twin shop-floor — CIRP Annals
- Van chatbot naar AI Operating System (intern artikel)
- AI-onboarding in 10 stappen (intern artikel)
Op zoek naar een AI-keynote-spreker voor je event in 2026?
Live Digital-Twin-demo’s, neurowetenschappelijk onderbouwde inhoud, in het Nederlands, Engels of Duits. Stuur een bericht — we bevestigen de match binnen 24 uur.
Over de auteur: Dr. Jonathan T. Mall is cognitief neuropsycholoog, CIO en co-founder van neuroflash. Hij ontwikkelt AI-gestuurde systemen voor Predictive Audience Intelligence en spreekt regelmatig over het snijvlak van psychologie, AI en productiviteit. Contact: jonathanmall.com · LinkedIn.