Die Lock-in-Falle: Dein KI-Wissen verschwindet mit jedem Anbieterwechsel
Stell dir vor, du hast monatelang mit einem KI-Assistenten gearbeitet. Du hast ihm beigebracht, wie du E-Mails schreibst, wie dein Unternehmen funktioniert, welche Kunden wichtig sind. Der Assistent kennt deine Vorlieben, deine Abkuerzungen, deine Arbeitsweise. Dann kommt ein neues Modell auf den Markt — besser, schneller, guenstiger. Du wechselst. Und alles beginnt von vorn.
Das ist die Realitaet fuer die meisten Menschen, die heute mit KI arbeiten. Ihr gesamtes Wissen lebt in Chat-Verlaeufen. In Konversationen, die an ein bestimmtes Produkt gebunden sind. Neues Abo? Neuer Anbieter? Alles weg. Deine Prompts, dein Kontext, deine muehsam aufgebauten Praeferenzen — verschwunden wie eine geloeschte Datei.
Ich nenne das die Lock-in-Falle. Und sie betrifft nicht nur Einzelpersonen, sondern ganze Unternehmen. Teams, die ihr Prozesswissen in ChatGPT-Threads verstecken. Abteilungen, die ihre besten Prompts in Slack-Nachrichten vergraben. Fuehrungskraefte, die nicht einmal wissen, welches KI-Wissen in ihrem Unternehmen existiert — weil es nirgendwo dokumentiert ist.
Es gibt einen besseren Weg.
Der File-First-Ansatz: Dein Wissen gehoert in Dateien, nicht in Chats
Bei neuroflash haben wir vor ueber einem Jahr angefangen, unser KI-System fundamental anders aufzubauen. Statt unser Wissen in Chat-Verlaeufen zu speichern, legen wir alles als Markdown-Dateien in Ordnern ab. Klingt simpel? Ist es auch. Und genau das ist der Punkt.
Die Struktur sieht so aus:
CLAUDE.md— deine persoenliche Bedienungsanleitung. Wer du bist, wie du arbeitest, welche Regeln gelten. Wenn die KI diese Datei liest, weiss sie sofort, mit wem sie es zu tun hat.skills/— jeder Arbeitsablauf ist ein Ordner mit einerSKILL.mdund optionalen Skripten. Blog schreiben? Skill. LinkedIn-Post erstellen? Skill. Rechnung pruefen? Skill.entities/— Menschen, Unternehmen, Projekte als strukturierte.md-Dateien. Dein CRM in Textform.memory/— was die KI ueber die Zusammenarbeit mit dir gelernt hat. Korrekturen, Praeferenzen, Erkenntnisse.
Das sind einfach Textdateien. Keine Datenbank. Kein proprietaeres Format. Kein Vendor-Lock-in. Du kannst sie mit jedem Texteditor oeffnen, mit Git versionieren und per Dropbox synchronisieren.
Andrej Karpathy — ehemaliger KI-Chef bei Tesla und einer der einflussreichsten Koepfe der KI-Forschung — hat es kuerzlich auf den Punkt gebracht: Die Zukunft gehoert Systemen, in denen Menschen und KI gemeinsam an Dateien arbeiten. Nicht Systeme, in denen die KI alles im Verborgenen macht.
Warum dich das modellunabhaengig macht
Heute laeuft unser System auf Claude Code von Anthropic. Morgen koennte es GPT-5, Gemini 3 oder ein Open-Source-Modell auf eigenen Servern sein. Der Wechsel? Motor austauschen, Dateien behalten.
Skills bleiben. Entities bleiben. Memories bleiben. Null Migrationskosten.
Das ist kein theoretisches Szenario. Wir haben es schon gemacht. Als wir von einem Modell zum anderen gewechselt haben, hat es keine 30 Minuten gedauert. Ordner kopieren, Konfiguration anpassen, weiterarbeiten. Alles Wissen — die hunderten Skills, die tausenden Entities, die gesammelten Erinnerungen — alles war sofort verfuegbar.
Vergleich das mit dem ueblichen Ansatz: Du wechselst von ChatGPT zu Claude und faengst bei null an. Kein Kontext. Keine Praeferenzen. Keine gelernten Muster. Als wuerdest du einen neuen Mitarbeiter einstellen, der noch nie von deinem Unternehmen gehoert hat.
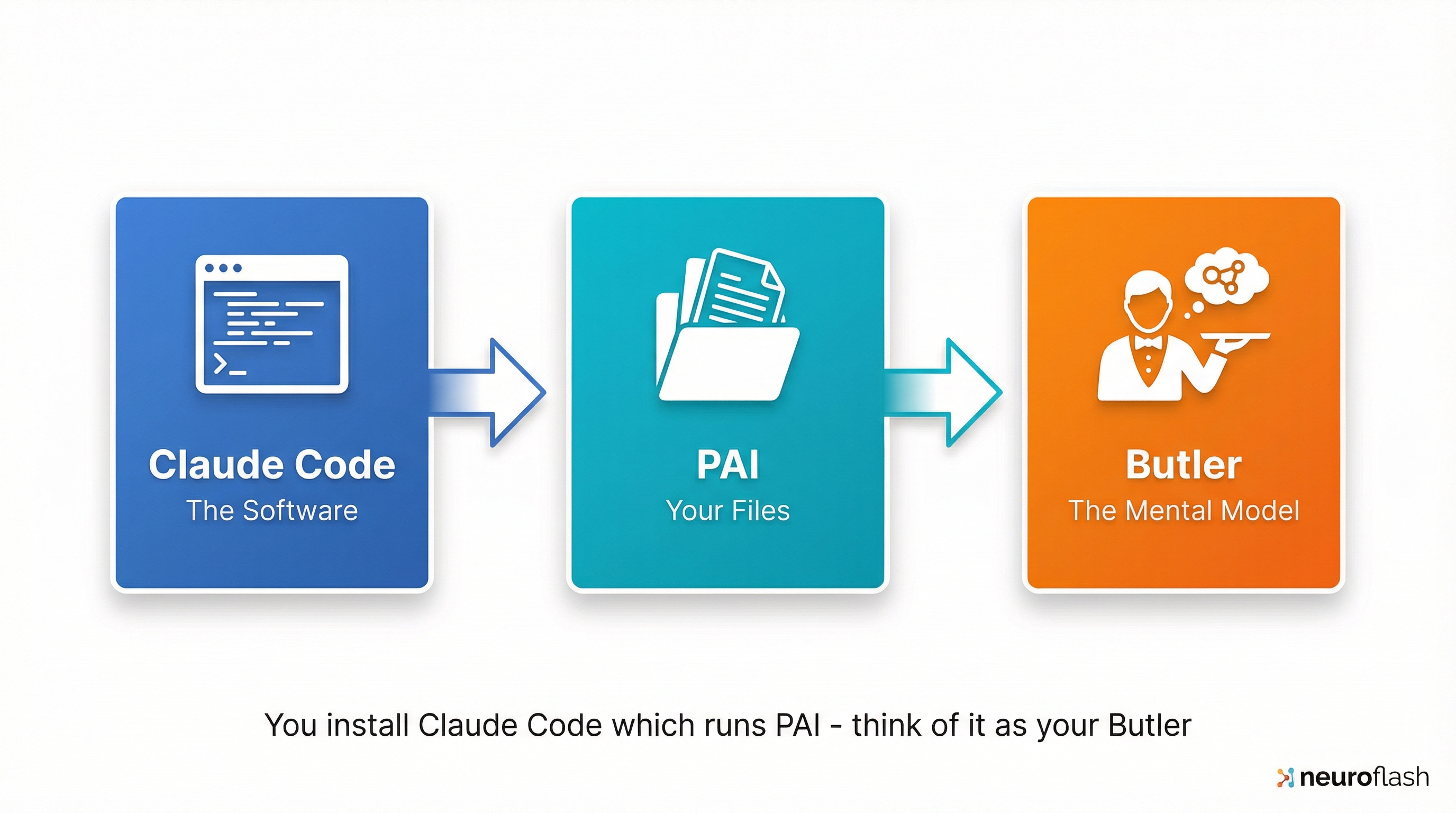
Software (Claude Code), Dateien (PAI) und mentales Modell (Butler) gehören zusammen, aber sind austauschbar — nur die Dateien gehören dauerhaft dir.
Du wirst zum digitalen Zwilling
Hier wird es richtig interessant. Wenn du dokumentierst, wie du arbeitest, wen du kennst, was du gelernt hast und welchen Prozessen du folgst — dann erstellst du eine maschinenlesbare Version von dir selbst. Einen digitalen Zwilling deiner Arbeit.
Nicht im gruseligen Ueberwachungs-Sinne. Sondern im praktischen: Jede KI, die deine Dateien liest, kann in deinem Namen handeln. Mit deinem Kontext. Nach deinen Regeln. Sie weiss, dass du E-Mails lieber kurz haeltst, dass du bei Blog-Artikeln immer eine SEO-Analyse brauchst, dass du mittwochs nie Termine vor 10 Uhr haben willst.
Die Forschung zu digitalen Zwillingen — urspruenglich aus dem industriellen Kontext (Tao et al., 2017) — beschreibt genau dieses Prinzip: ein virtuelles Abbild, das den Zustand und das Verhalten seines realen Gegenstuecks widerspiegelt. Wir uebertragen das auf die Wissensarbeit.
Fuer Unternehmen ist das noch maerchtiger. Wenn die Skills und Entities jedes Teammitglieds in eine gemeinsame Bibliothek fliessen, wird das Unternehmen selbst zum digitalen Zwilling. Neuer Mitarbeiter? Er erbt das kollektive Wissen am ersten Tag. Er klont das Skill-Repository, laesst den Onboarding-Skill laufen und ist innerhalb von Stunden produktiv.
Eine SKILL.md-Datei ist im Grunde eine API-Spezifikation fuer einen menschlichen Arbeitsablauf. Jede hinreichend leistungsfaehige KI kann sie lesen und ausfuehren. Das ist dein digitaler Zwilling in Aktion.
Der Lernkreislauf: Dateien vergessen nicht
Das Schoene an diesem System ist der Lernkreislauf. Jedes Mal, wenn du die KI korrigierst, kannst du diese Korrektur als Memory speichern. Jedes Mal, wenn du ein neues Problem loest, kannst du es als Skill dokumentieren. Die Dateien wachsen. Der Zwilling wird vollstaendiger.
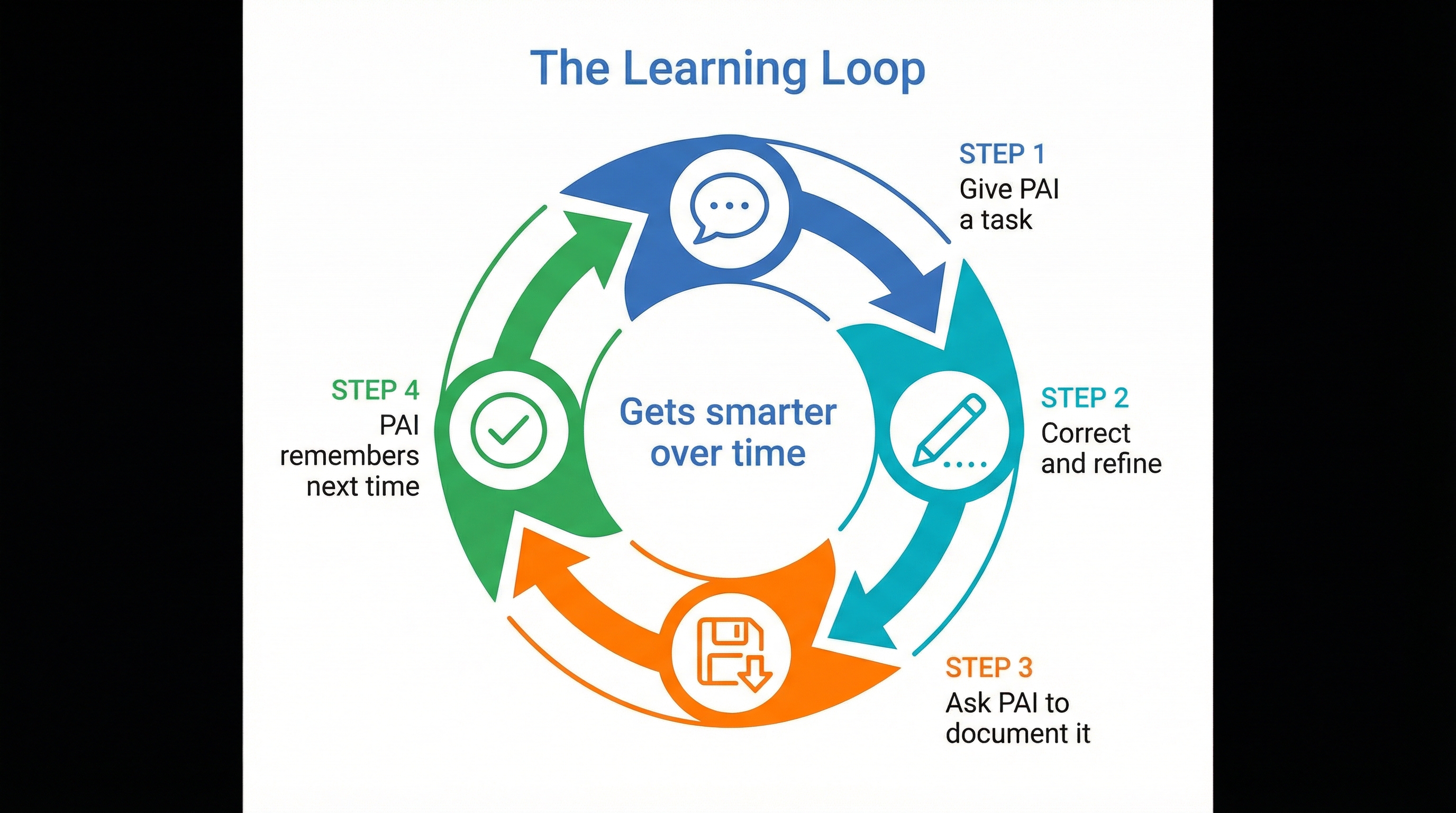
Der Lernkreislauf macht aus jeder Korrektur eine dauerhafte Memory-Datei — anders als ein Modell, das zwischen Sitzungen vergisst, wächst dein digitaler Zwilling mit jeder Interaktion.
Und anders als ein trainiertes Modell, das zwischen Sitzungen vergisst: Dateien vergessen nicht.
Ein Beispiel aus unserem Alltag: Letzte Woche hat die KI einen LinkedIn-Post mit einem bestimmten Tonfall geschrieben, der mir nicht gefiel. Ich habe sie korrigiert, und die Korrektur wurde automatisch in einer Memory-Datei gespeichert. Ab jetzt — egal ob ich morgen, naechste Woche oder in drei Monaten einen LinkedIn-Post schreibe — wird diese Praeferenz beruecksichtigt. Nicht weil das Modell “gelernt” hat, sondern weil die Datei es weiss.
Dieses Prinzip skaliert. Nach Monaten der Nutzung enthaelt unser System hunderte solcher Korrekturen und Erkenntnisse. Jede einzelne ist ein kleines Stueck dokumentiertes Wissen, das den digitalen Zwilling praeziser macht. Und jede einzelne ueberlebt jeden Modellwechsel.
Drei praktische Beispiele
1. Modellwechsel in 30 Minuten
Als wir von einem KI-Modell zu einem anderen gewechselt haben, war der Prozess trivial: Ordner kopieren, Engine-Konfiguration anpassen, fertig. Alle Skills, alle Entities, alle Memories — sofort verfuegbar. Kein Retraining, kein Prompt-Engineering von Grund auf, kein Wissensverlust. Der neue Motor hat die gleichen Dateien gelesen und konnte sofort arbeiten.
2. Onboarding am ersten Tag
Wenn ein neues Teammitglied bei uns anfaengt, klont es das gemeinsame Skill-Repository. Dort findet es dokumentierte Arbeitsablaeufe fuer alles: wie wir Blog-Artikel schreiben, wie wir Rechnungen pruefen, wie wir Kundendaten pflegen. Es gibt einen Onboarding-Skill, der Schritt fuer Schritt durch die Einrichtung fuehrt. Statt wochenlanger Einarbeitung ist die Person innerhalb von Stunden produktiv — weil der digitale Zwilling des Unternehmens ihr alles erklaert.
3. Versionskontrolle fuer Prozesse
Weil unsere Skills in Git liegen, koennen wir sehen, wie sich Prozesse ueber die Zeit entwickelt haben. Wir koennen Fehler zurueckrollen. Wir koennen an Verbesserungen zusammenarbeiten, genau wie Entwickler an Code. Eine SKILL.md-Datei hat eine Git-History. Ein Chat-Verlauf nicht.
Häufig gestellte Fragen
Was ist ein digitaler Zwilling in der KI?
Ein digitaler Zwilling ist dein persönliches Wissenssystem in Dateiform. Es speichert deine Erfahrungen, Vorlieben und Arbeitsweisen so, dass jeder KI-Agent darauf zugreifen kann – unabhängig vom Anbieter oder Modell.
Sind Markdown-Skills modellunabhängig?
Ja, Markdown-Skills sind vollständig modellunabhängig. Da sie als einfache Textdateien vorliegen, kann jedes KI-Modell sie lesen und ausführen. Du bist nicht an einen bestimmten Anbieter gebunden und kannst jederzeit wechseln.
Wie mache ich mich unabhängig von einem KI-Anbieter?
Speichere dein Wissen in lokalen Dateien statt in Cloud-Chats. Nutze Markdown für Workflows und Vorlagen, die jedes Modell versteht. So bleibt dein aufgebautes Wissen bei dir, egal ob du Claude, GPT oder ein anderes Modell verwendest.
Die Software ist austauschbar. Deine Dateien sind es nicht.
Das ist die zentrale Erkenntnis, die ich dir mitgeben moechte: Du trainierst keine KI. Du baust einen digitalen Zwilling davon, wie du arbeitest. Und jede KI kann diesen Zwilling bewohnen.
Claude Code, Copilot, was auch immer als naechstes kommt — das ist die Software. Sie ist austauschbar. Deine Dateien — die Skills, die Entities, die Memories, die Instruktionen — das sind du. Das ist dein Unternehmen. Das ist das eigentliche geistige Eigentum.
Nicht in jemandes Kopf eingesperrt. Nicht in einem proprietaeren Tool vergraben. In einfachen Textdateien, die jeder lesen, versionieren und teilen kann.
Wenn du morgen anfangen willst: Erstelle einen Ordner. Schreib eine CLAUDE.md (oder wie auch immer du sie nennen willst) mit einer Beschreibung von dir und deiner Arbeit. Dokumentiere deinen ersten Arbeitsablauf als Skill. Lege eine Entity fuer dein wichtigstes Projekt an. Das sind vielleicht 30 Minuten Arbeit.
Aber diese 30 Minuten machen dich unabhaengig. Von jedem Modell. Von jedem Anbieter. Von jeder Mode, die morgen in der KI-Welt kommt und uebermorgen wieder verschwindet.
Dein digitaler Zwilling gehoert dir. Sorge dafuer, dass er in Dateien lebt — nicht in fremden Chats.
Quellen & weiterfuehrende Artikel
- Claude Code — Anthropic Dokumentation
- Andrej Karpathy — KI-Forschung und Perspektiven
- Tao et al. (2017): Digital twin shop-floor — CIRP Annals
- Vom Chatbot zum AI Operating System (interner Artikel)
- KI-Onboarding in 10 Schritten (interner Artikel)
Du suchst einen KI-Keynote-Speaker für dein Event 2026?
Live-Digital-Twin-Demos, neurowissenschaftlich fundierte Inhalte, auf Deutsch, Englisch oder Niederländisch. Schreib mir kurz — die Passung klären wir in 24 Stunden.
Über den Autor: Dr. Jonathan T. Mall ist kognitiver Neuropsychologe, CIO und Co-Founder von neuroflash. Er entwickelt KI-gestützte Systeme für Predictive Audience Intelligence und spricht regelmäßig über die Schnittstelle von Psychologie, KI und Produktivität. Kontakt: jonathanmall.com · LinkedIn.