The Lock-in Trap: Your AI Knowledge Disappears with Every Provider Switch
Imagine you’ve spent months working with an AI assistant. You’ve taught it how you write emails, how your company operates, which clients matter most. The assistant knows your preferences, your abbreviations, your workflow. Then a new model hits the market — better, faster, cheaper. You switch. And everything starts from scratch.
That’s the reality for most people working with AI today. All their knowledge lives in chat histories. In conversations tied to a specific product. New subscription? New provider? Gone. Your prompts, your context, your painstakingly built preferences — vanished like a deleted file.
I call this the lock-in trap. And it doesn’t just affect individuals — it hits entire companies. Teams that hide their process knowledge in ChatGPT threads. Departments that bury their best prompts in Slack messages. Executives who don’t even know what AI knowledge exists in their organization — because it’s documented nowhere.
There’s a better way.
The File-First Approach: Your Knowledge Belongs in Files, Not Chats
At neuroflash, we started building our AI system fundamentally differently over a year ago. Instead of storing our knowledge in chat histories, we save everything as Markdown files in folders. Sounds simple? It is. And that’s exactly the point.
The structure looks like this:
CLAUDE.md— your personal instruction manual. Who you are, how you work, which rules apply. When the AI reads this file, it immediately knows who it’s dealing with.skills/— every workflow is a folder with aSKILL.mdand optional scripts. Write a blog post? Skill. Create a LinkedIn post? Skill. Review an invoice? Skill.entities/— people, companies, projects as structured.mdfiles. Your CRM in plain text.memory/— what the AI has learned about working with you. Corrections, preferences, insights.
These are just text files. No database. No proprietary format. No vendor lock-in. You can open them with any text editor, version them with Git, and sync them via Dropbox.
Andrej Karpathy — former AI lead at Tesla and one of the most influential minds in AI research — recently put it perfectly: The future belongs to systems where humans and AI work together on files. Not systems where the AI does everything behind closed doors.
Why This Makes You Model-Independent
Today our system runs on Claude Code by Anthropic. Tomorrow it could be GPT-5, Gemini 3, or an open-source model on our own servers. The switch? Swap the engine, keep the files.
Skills stay. Entities stay. Memories stay. Zero migration costs.
This isn’t a theoretical scenario. We’ve already done it. When we switched from one model to another, it took less than 30 minutes. Copy the folders, adjust the configuration, keep working. All the knowledge — the hundreds of skills, the thousands of entities, the accumulated memories — everything was instantly available.
Compare that to the usual approach: You switch from ChatGPT to Claude and start from zero. No context. No preferences. No learned patterns. It’s like hiring a new employee who has never heard of your company.
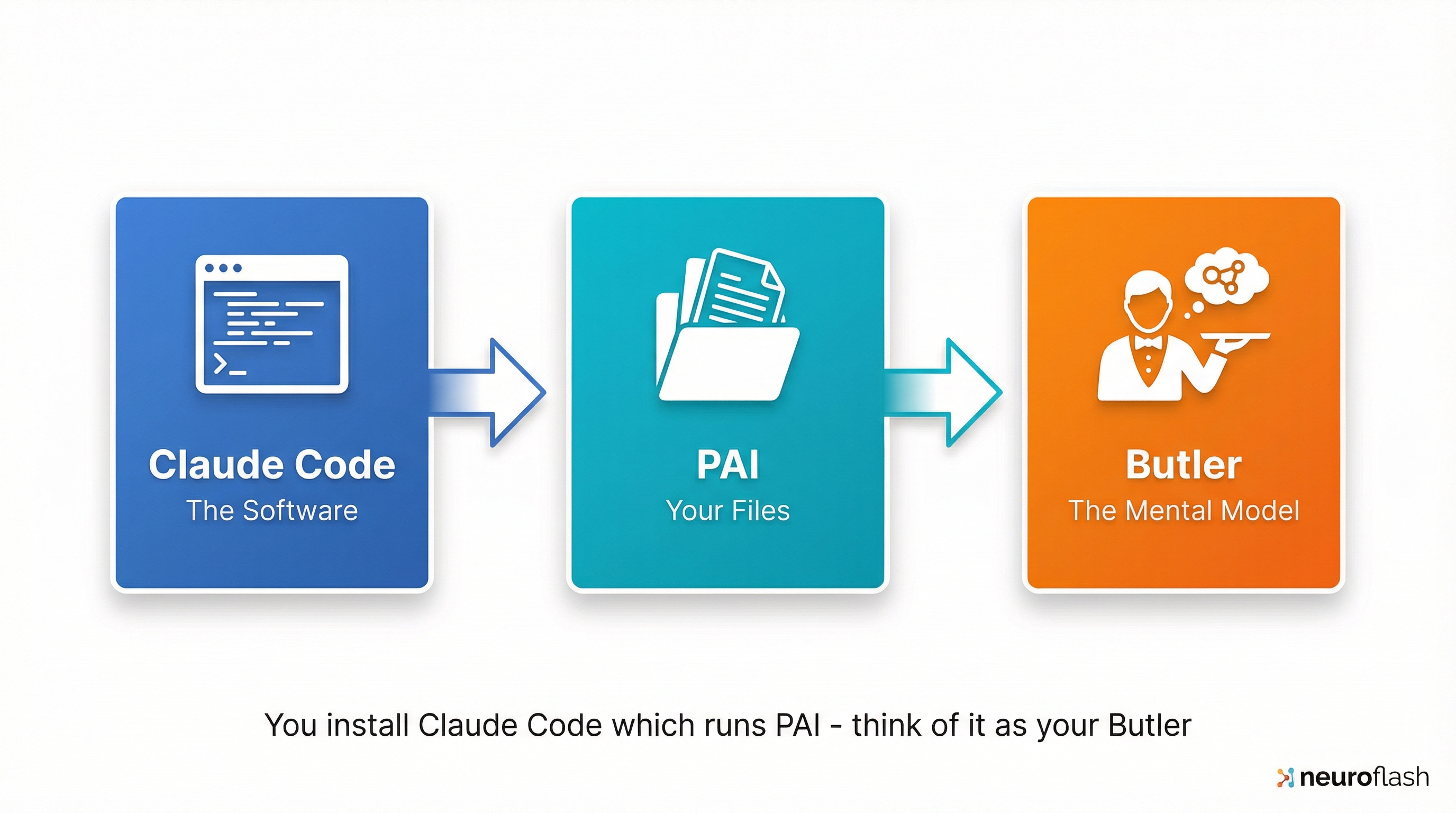
Software (Claude Code), files (PAI), and mental model (Butler) belong together but stay swappable — only the files are permanently yours.
You Become a Digital Twin
This is where it gets really interesting. When you document how you work, who you know, what you’ve learned, and which processes you follow — you’re creating a machine-readable version of yourself. A digital twin of your work.
Not in the creepy surveillance sense. In the practical sense: Any AI that reads your files can act on your behalf. With your context. By your rules. It knows you prefer emails short, that you always need an SEO analysis for blog articles, that you never want meetings before 10 AM on Wednesdays.
Research on digital twins — originally from the industrial context (Tao et al., 2017) — describes exactly this principle: a virtual representation that mirrors the state and behavior of its real-world counterpart. We’re applying this to knowledge work.
For companies, this is even more powerful. When every team member’s skills and entities flow into a shared library, the company itself becomes a digital twin. New hire? They inherit the collective knowledge on day one. They clone the skill repository, run the onboarding skill, and are productive within hours.
A SKILL.md file is essentially an API specification for a human workflow. Any sufficiently capable AI can read and execute it. That’s your digital twin in action.
The Learning Loop: Files Don’t Forget
The beauty of this system is the learning loop. Every time you correct the AI, you can save that correction as a memory. Every time you solve a new problem, you can document it as a skill. The files grow. The twin becomes more complete.
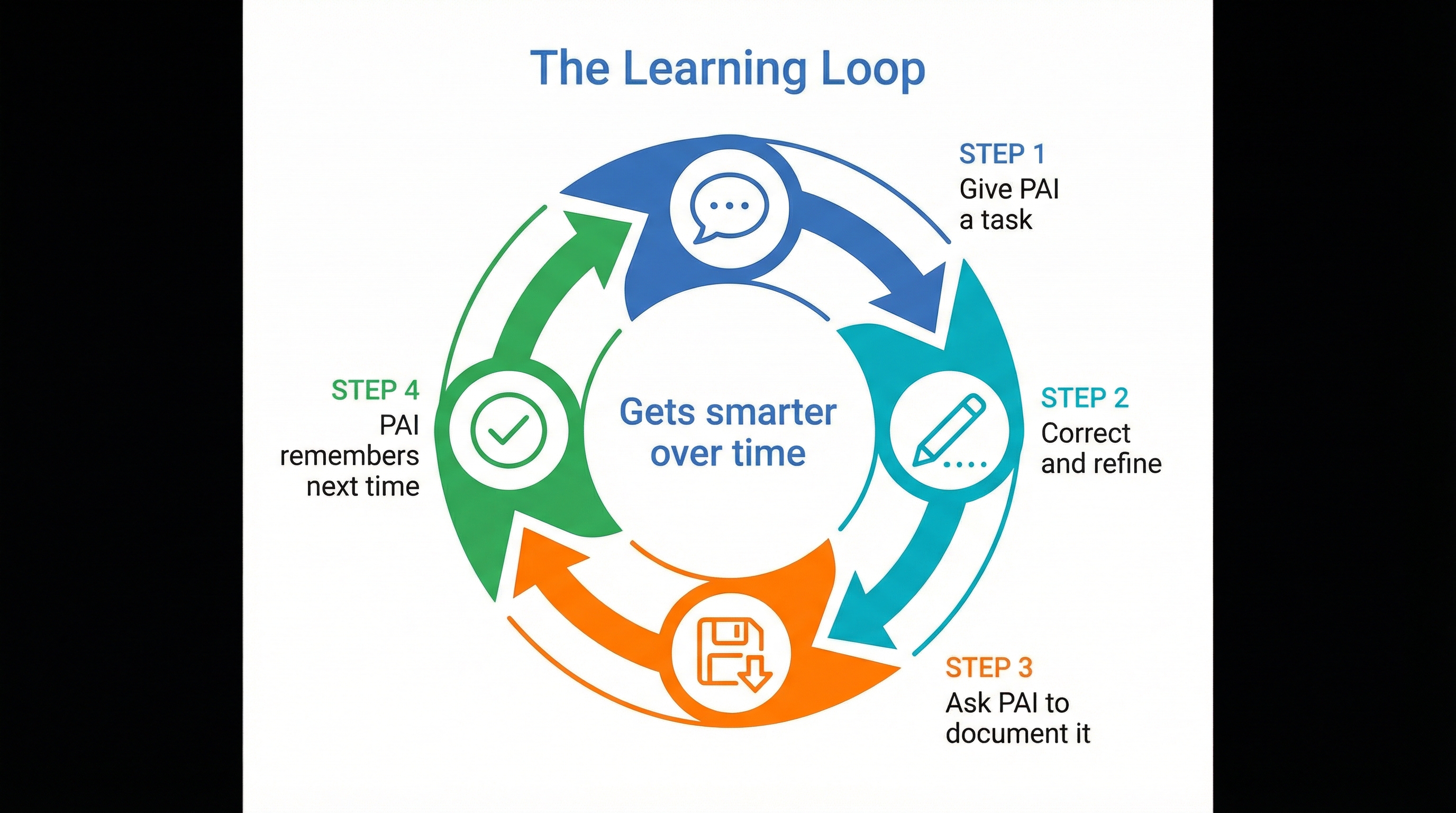
The learning loop turns every correction into a persistent memory file — unlike a model that forgets between sessions, your digital twin grows with every interaction.
And unlike a trained model that forgets between sessions: Files don’t forget.
An example from our daily work: Last week the AI wrote a LinkedIn post in a certain tone that I didn’t like. I corrected it, and the correction was automatically saved to a memory file. From now on — whether I write a LinkedIn post tomorrow, next week, or in three months — that preference will be respected. Not because the model “learned,” but because the file knows.
This principle scales. After months of use, our system contains hundreds of such corrections and insights. Each one is a small piece of documented knowledge that makes the digital twin more precise. And each one survives every model switch.
Three Practical Examples
1. Model Switch in 30 Minutes
When we switched from one AI model to another, the process was trivial: copy the folders, adjust the engine configuration, done. All skills, all entities, all memories — instantly available. No retraining, no prompt engineering from scratch, no knowledge loss. The new engine read the same files and could start working immediately.
2. Onboarding on Day One
When a new team member joins us, they clone the shared skill repository. There they find documented workflows for everything: how we write blog articles, how we review invoices, how we maintain customer data. There’s an onboarding skill that walks them through setup step by step. Instead of weeks of ramp-up, the person is productive within hours — because the company’s digital twin explains everything to them.
3. Version Control for Processes
Because our skills live in Git, we can see how processes have evolved over time. We can roll back mistakes. We can collaborate on improvements, just like developers collaborate on code. A SKILL.md file has a Git history. A chat thread does not.
Frequently Asked Questions
What is a digital twin in AI?
A digital twin is your personal knowledge system in file form. It stores your experiences, preferences, and workflows so that any AI agent can access them – regardless of provider or model.
Are Markdown skills model-independent?
Yes, Markdown skills are fully model-independent. Since they exist as plain text files, any AI model can read and execute them. You are not locked into any specific provider and can switch at any time.
How do I become independent of an AI provider?
Store your knowledge in local files instead of cloud chats. Use Markdown for workflows and templates that any model understands. This way, your accumulated knowledge stays with you whether you use Claude, GPT, or any other model.
The Software Is Replaceable. Your Files Are Not.
This is the key insight I want to leave you with: You’re not training an AI. You’re building a digital twin of how you work. And any AI can inhabit that twin.
Claude Code, Copilot, whatever comes next — that’s the software. It’s replaceable. Your files — the skills, the entities, the memories, the instructions — that’s you. That’s your company. That’s the real intellectual property.
Not locked in someone’s head. Not buried in a proprietary tool. In simple text files that anyone can read, version, and share.
If you want to start tomorrow: Create a folder. Write a CLAUDE.md (or whatever you want to call it) with a description of yourself and your work. Document your first workflow as a skill. Create an entity for your most important project. That’s maybe 30 minutes of work.
But those 30 minutes make you independent. Of any model. Of any provider. Of any trend that arrives in the AI world tomorrow and disappears the day after.
Your digital twin belongs to you. Make sure it lives in files — not in someone else’s chats.
Sources & Further Reading
- Claude Code — Anthropic Documentation
- Andrej Karpathy — AI Research and Perspectives
- Tao et al. (2017): Digital twin shop-floor — CIRP Annals
- From Chatbot to AI Operating System (internal article)
- AI Onboarding in 10 Steps (internal article)
Looking for an AI keynote speaker for your 2026 event?
Live Digital-Twin demos, neuroscience-grounded content, in English, German, or Dutch. Drop a line — we’ll confirm fit within 24 hours.
About the Author: Dr. Jonathan T. Mall is a cognitive neuropsychologist, CIO, and co-founder of neuroflash. He develops AI-powered systems for Predictive Audience Intelligence and regularly speaks about the intersection of psychology, AI, and productivity. Contact: jonathanmall.com · LinkedIn.