Vor zwei Tagen — am 14. April 2026 — hat eine amerikanische SEO-Agentur den ersten kostenlosen Diagnose-Test für KI-Sichtbarkeit veröffentlicht. Die Pressemitteilung macht eine steile Behauptung: Die meisten Marken sind für ChatGPT, Claude, Gemini und Perplexity praktisch unsichtbar — selbst wenn sie in der klassischen Google-Suche gut ranken.
Stimmt das? Wir haben es geprüft. Bei neuroflash scannen wir seit Monaten systematisch deutsche und europäische Marken auf ihre KI-Sichtbarkeit. Bis heute: 293 Marken — von Volkswagen über Der Spiegel bis zu spezialisierten B2B-Mittelständlern.
Das Ergebnis ist differenzierter als die amerikanische Schlagzeile — aber in einer Hinsicht dramatischer: Selbst Unternehmen, die man sofort kennt, bekommen keine Empfehlung. Eine vertiefende Einordnung zum Mechanismus der KI-Empfehlung findest du in meinem Pillar-Artikel „Empfohlen oder unsichtbar: Warum es in der KI-Suche kein Dazwischen gibt”.
Das methodische Fundament: Was wir genau messen
Bevor die Zahlen kommen, kurz die Methode. Wir fragen die KI nicht: „Ist Volkswagen gut?” Das würde jede KI mit „Ja, weltbekannte Marke” beantworten. Stattdessen stellen wir realistische Käuferfragen ohne Markenname:
- „Welches neue Auto ist aktuell sparsam, sicher und alltagstauglich?”
- „Welche kompakten SUVs oder Limousinen bieten gutes Preis-Leistungs-Verhältnis?”
- „Wo kann ich ein neues Auto mit Probefahrt und Finanzierung vergleichen?”
So fragen echte Käufer. Die KI muss selbst entscheiden, welche Marken sie empfiehlt. Wir messen dann: Taucht die Zielmarke auf? An welcher Position? Werden Konkurrenten stattdessen empfohlen?
Pro Unternehmen laufen zehn Abfragen entlang der AIDA-Kundenreise (Aufmerksamkeit → Interesse → Verlangen → Handlung) für zwei Zielgruppen. Das Ergebnis: ein Potenzial-Score von 0 bis 100.
Der entscheidende Unterschied: Nicht wie KI fragt, sondern wie deine Zielgruppe wirklich fragt
An dieser Stelle trennt sich die Spreu vom Weizen. Die meisten AI-Visibility-Tools testen eine gefährliche Illusion: Sie prüfen KI-perfekte Suchanfragen — Anfragen, die kein echter Mensch jemals tippen würde. Etwas wie „Beste vollautomatische Lagerautomatisierung B2B Deutschland Vergleich” — so schreibt die KI, niemand sonst.
Unsere Daten aus echten Chat-Interaktionen zeigen: Weniger als 10 % der realen Anfragen sehen so aus, wie wir auf Keywords optimieren. Die meisten sind conversational, unpräzise, ohne Fragezeichen, manchmal mit Tippfehlern. Wer für die KI-Phantasie-Version optimiert, optimiert am Markt vorbei.
Deswegen verwenden wir bei neuroflash Digital Twins — psychologische Zwillinge deiner Zielgruppe, die auf drei Ebenen echter Daten basieren:
- Über 1 Million echte Umfrageantworten von realen Menschen. Jede Person beantwortet bis zu 250 Fragen zu ihren neuropsychologischen Treibern: Risikobereitschaft, Offenheit, Kaufmotiven, Vertrauensfaktoren. Das ist keine LLM-Persona aus einem demografischen Prompt — das ist ein psychologisches Profil mit belastbarer Tiefe.
- Über 20 Millionen reale Chat-Interaktionen aus unserer Plattform. Wir wissen, wie lang echte Anfragen sind, ob sie Fragezeichen benutzen, wie B2B-Einkäufer anders schreiben als Endverbraucher. Diese Metadaten kalibrieren, wie eine Anfrage formuliert wird, nicht nur was gefragt wird.
- Psychologisch abgeleitete Kaufabsicht. Statt nach Keywords zu optimieren, simulieren wir, welche Fragen deine Zielgruppe in welcher Phase des Kaufprozesses wirklich stellt — Aufmerksamkeit, Interesse, Verlangen, Handlung.
Das Ergebnis: Die zehn Käuferfragen, die wir pro Marke testen, sind kalibriert auf deine tatsächliche Zielgruppe — nicht auf das, was ChatGPT selbst für eine „gute Frage” hält. Validität: 75–85 % Übereinstimmung mit echten Menschen in über 80 publizierten Studien. In unseren internen Cases erreichen wir Werte bis zu 92 % (Oettinger Verlag) und 98 % (Essity-Case).
Das ist der Unterschied zwischen „interessante Zahlen auf einem Dashboard” und „strategische Entscheidungsgrundlage, wo du deine Content-Offensive ansetzen solltest”. Wenn deine Digital Twins dir sagen, dass deine Marke in einer bestimmten Kaufphase fehlt, ist das kein theoretisches Risiko — das ist verlorener Umsatz, den du jetzt zurückholen kannst.
Ehrliche Einordnung: Was dieser Scan ist — und was er nicht ist
Bevor du die Zahlen siehst, eine wichtige Transparenz: Der hier gezeigte Scan deckt pro Marke zehn Abfragen ab. Das ist weniger als 1 % dessen, was wir in einem echten Kunden-Projekt analysieren.
Ein vollständiger AI-Visibility-Audit bei neuroflash umfasst typischerweise über 2.000 simulierte Käuferanfragen und mehr als 200.000 analysierte KI-Antworten — aufgebrochen nach Zielgruppensegmenten, Kaufphasen, Wettbewerbern, Sprache, Plattform (ChatGPT vs. Perplexity vs. Gemini) und Quellenart. Das ist die Basis, auf der sich Content-Strategie und Priorisierung belastbar ableiten lassen.
Was du in diesem Artikel siehst, ist also ein Snapshot-Glimpse, kein wissenschaftlicher Vergleich. Interessant wird er durch die schiere Anzahl gescannter Marken: 293 deutsche Unternehmen nebeneinander ergeben ein belastbares Mustererkennen, auch wenn jede einzelne Zahl für eine einzelne Marke natürlich eine Momentaufnahme bleibt. KI-Empfehlungen ändern sich — mit jedem neuen Modell, jedem Content-Update deiner Wettbewerber, jeder neuen Drittquelle. Eine einzelne Zahl aus April 2026 darfst du nicht als dein Urteil im Oktober 2026 lesen.
Die Richtung ist trotzdem deutlich. Und sie wird sich ohne aktives Handeln eher verstärken als abschwächen.
Das Ergebnis: Drei Welten existieren nebeneinander
Die 293 gescannten Marken verteilen sich nicht gleichmäßig — sie zerfallen in drei Gruppen:
- Die Unsichtbaren (14 %): Score unter 40. Diese Marken werden bei relevanten Käuferfragen praktisch nie empfohlen. Der durchschnittliche Kunde findet sie in ChatGPT-Recherchen nicht.
- Die Halbsichtbaren (63 %): Score zwischen 40 und 80. Sie tauchen auf — aber inkonsistent. Bei manchen Fragen ganz vorn, bei anderen komplett abwesend. Das ist die gefährlichste Kategorie, weil der Verlust versteckt bleibt.
- Die Empfohlenen (23 %): Score über 80. Diese Marken dominieren die KI-Antworten für ihre Kategorie. Sie sind die Gewinner.
Der Mittelwert über alle 293 Marken: 59 von 100 Punkten. Die durchschnittliche Erwähnungsrate: 42 %. Das heißt: In mehr als der Hälfte der kaufrelevanten Fragen erscheint die durchschnittliche Marke nicht.
Die Daten im Überblick: 293 Marken, 4 Datenpunkte
Score-Verteilung (n=293)
Top 10 Performer
Bekannte Marken im Mittelfeld & darunter
Die Überraschungen: Wer führt, wer verliert
Die Rangliste bricht die Intuition an mehreren Stellen:
Top-Performer (Score 90+):
- Škoda: 98/100 (Erwähnung 100 %)
- TRUMPF: 94/100
- Pepperl+Fuchs: 93/100
- DER SPIEGEL: 92/100
Starke Mitte (80-88): BRITA (88), Vaillant (88), HELLA (88), apetito (88), Kienbaum (88), Rotkäppchen (88), BARMER (87), Zalando (86), Samsung (85), Workday (83), Rossmann (82), KPMG (82), Telekom (82), Miele (82).
Überraschend schwach (unter 70):
- Volkswagen: 62/100 (Erwähnung nur 50 %)
- SIGNAL IDUNA: 62/100
- GoDaddy: 58/100
- BARC: 46/100
- Universal Investment: 38/100 (Erwähnung 38 %)
Volkswagen, der größte deutsche Automobilhersteller, landet nur im Mittelfeld. Das klingt abstrakt. Konkret heißt es das:
Die Volkswagen-Paradoxie: Die Tochter schlägt die Mutter
In unseren vier Abfragen für private Autokäufer — den Kern des VW-Geschäfts — erscheint Volkswagen kein einziges Mal in der Empfehlung von ChatGPT:
- „Welches neue Auto ist aktuell sparsam, sicher und alltagstauglich?” → Empfohlen: Honda, Toyota, Hyundai, Kia
- „Welche kompakten SUVs oder Limousinen bieten gutes Preis-Leistungs-Verhältnis?” → Empfohlen: Škoda, Kia, Nissan, MG
- „Welches Auto hat niedrige Unterhaltskosten und gute Reichweite?” → Empfohlen: Škoda, Kia, Toyota, Opel
- „Wo kann ich ein neues Auto mit Probefahrt und Finanzierung vergleichen?” → Empfohlen: Carwow, AutoScout24
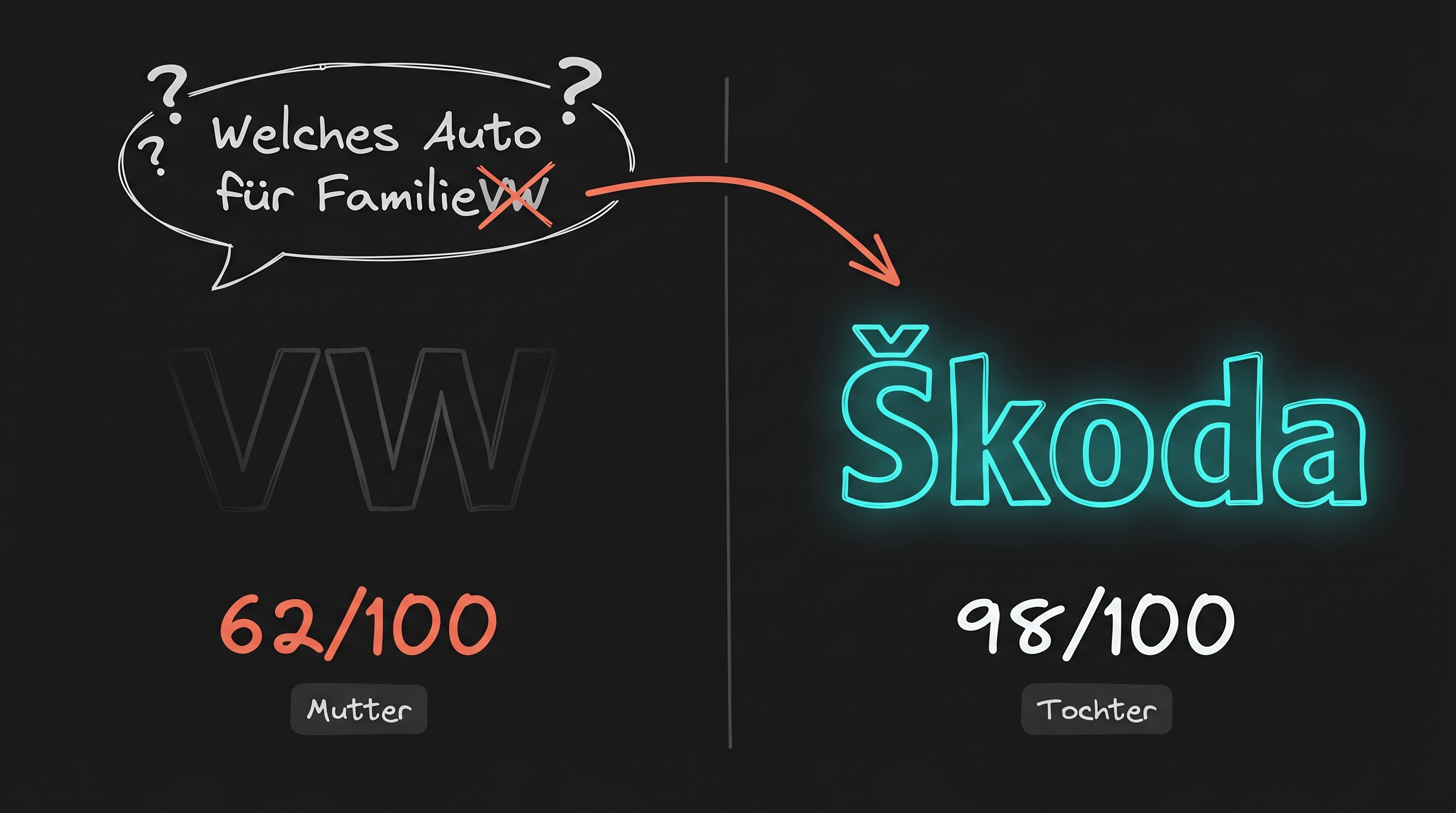
Der Clou: Škoda gehört zu Volkswagen. Der Konzern empfiehlt sich in ChatGPT selbst — aber über die Tochter, nicht über die Dachmarke. Škoda erreicht 98/100, Volkswagen 62/100. Ein Unterschied von 36 Punkten innerhalb desselben Konzerns.
Aus psychologischer Sicht ist das logisch: Škoda hat in den letzten Jahren erfolgreich als „Value-Marke” positioniert — konkreter, fassbarer, kategorienspezifisch. VW ist abstrakter, breiter — und verliert genau deshalb im Zeitalter der KI-Empfehlung, wo konkrete Use-Cases zählen.
Warum das ein Pipeline-Problem ist, kein Marketing-Problem
Die naheliegende Reaktion: „Das ist doch nur ein Sichtbarkeits-Thema.” Falsch. Drei Zahlen machen den Unterschied deutlich:
- 25 % der B2B-Einkäufer bevorzugen 2026 generative KI gegenüber Google für die Anbieterrecherche (Quelle: Column Five Media).
- Besucher, die über KI-Empfehlungen auf eine Website kommen, konvertieren mit 11-facher Rate gegenüber klassischem Suchtraffic.
- LLMs nennen im Schnitt nur 2,8 Marken pro Antwort. Es gibt keine Seite zwei.
Wer in den relevanten 2,8 nicht vorkommt, taucht im Kaufprozess nicht auf. Das ist der Unterschied zwischen „Traffic-Einbruch” und „Deal-Pipeline schrumpft”.
Das Muster: Was die Gewinner anders machen
Aus den 82 Marken mit Score über 80 extrahieren wir vier wiederkehrende Muster:
1. Kategorie-Dominanz statt Brand-Dominanz. TRUMPF steht für Laserschneiden, nicht für „Werkzeugmaschinenbau”. Pepperl+Fuchs für Sensorik, nicht für „Automatisierungstechnik”. Je klarer die Kategorie-Zuordnung, desto höher der Score.
2. Externe Zitate. Fast alle Top-Performer werden regelmäßig in Fachmedien, Branchenverzeichnissen und Vergleichsportalen genannt. LLMs ziehen diese Drittquellen als Autoritätssignal heran. Marken mit weniger als fünf externen Erwähnungen haben praktisch keine Chance auf eine KI-Empfehlung.
3. Strukturierte Inhalte. FAQPage-Schema, Produktvergleichstabellen, „Best of”-Seiten. Das sind Formate, die LLMs direkt extrahieren können. Wer nur Storytelling-Content produziert, bleibt unsichtbar.
4. Aktualität. Inhalte, die innerhalb der letzten 30 Tage aktualisiert wurden, bekommen laut Princeton GEO-Studie (KDD 2024) einen 6,5-fachen Zitations-Multiplikator. Wer seit 2023 nichts mehr publiziert hat, verschwindet.
Was jetzt zu tun ist
Drei Schritte, messbar in der eigenen Marke:
- Eigenen Score ermitteln. Nicht schätzen — testen. Formuliere zehn realistische Käuferfragen für deine Produktkategorie (ohne deine Marke zu nennen) und prüfe in ChatGPT, Perplexity und Google AI Overviews, ob du vorkommst. Dokumentiere, welche Konkurrenten stattdessen empfohlen werden. Oder nutze unseren kostenlosen Quick-Scan, der das in zwei Minuten automatisiert erledigt.
- Die drei Schwachstellen schließen. Top-10-Seiten mit Statistiken und Expertenzitaten anreichern (+41 % Sichtbarkeit), Schema-Markup implementieren (2-3x höhere Zitationsrate), GPTBot und PerplexityBot in robots.txt explizit erlauben.
- Drittquellen aufbauen. PR, Branchenverzeichnisse, Fachmedien, Vergleichsportale. Ziel: fünf externe Quellen pro Kernkategorie innerhalb der nächsten 90 Tage.
Fazit: Die Sichtbarkeitslücke ist größer, als die Vorstandsetage denkt
Unsere Daten widersprechen der amerikanischen „Fast alle Marken sind unsichtbar”-These nur in Nuancen. Ja, es gibt starke Performer. Aber nur 23 % der gescannten Marken erreichen eine Position, die belastbar „empfohlen” genannt werden kann (Score ≥ 80). Die restlichen 77 % sind entweder unsichtbar (14 %) oder inkonsistent sichtbar (63 %) — was im KI-Zeitalter praktisch dasselbe bedeutet.
Volkswagen ist das Lehrbuchbeispiel: Eine der bekanntesten Marken der Welt, 120 Jahre Geschichte, Milliarden an Markenwert — und in ChatGPT beim privaten Autokauf null Empfehlungen in vier Abfragen. Gleichzeitig dominiert die Tochter Škoda mit 98 von 100 Punkten.
Das ist keine Prognose. Das ist der Zustand am 16. April 2026. Und es wird sich nicht von selbst lösen — KI-Sichtbarkeit hat einen kumulativen Effekt: Wer einmal als Autorität erkannt wird, bleibt es. Wer fehlt, bleibt unsichtbar.
Welche deiner Konkurrenten werden empfohlen, wenn deine Kunden die KI fragen? Die Antwort ist messbar. Die Frage ist, ob du sie stellen willst.
Quellen & weiterführende Artikel
Externe Studien und Daten:
- Aggarwal et al. (2024): GEO — Generative Engine Optimization. Princeton / Georgia Tech / Allen Institute for AI / IIT Delhi. KDD 2024.
- First AI Visibility Diagnostic Reveals Most Brands Unrecognizable to ChatGPT (EIN Presswire, 14. April 2026).
- Column Five Media (2026): AI Search Visibility Stats That Might Surprise You.
- BCG (2026): Consumers Trust AI to Buy Better — Brands Must Adapt.
- Conveo (2026): Consumers Twice as Likely to Trust AI Over Family and Friends.
- Erlin.ai (2026): LLM Brand Visibility — Third-Party Citations as the Strongest Predictor.
Vertiefende Artikel auf jonathanmall.com:
- Empfohlen oder unsichtbar: Warum es in der KI-Suche kein Dazwischen gibt — der Pillar-Artikel zu Generative Engine Optimization.
- Die drei Wellen der KI im Marketing — warum Content-Generierung erst der Anfang war.
- Die Psychologie hinter erfolgreicher Markenkommunikation — warum externe Drittquellen als Vertrauenssignal so stark wirken.
- Der Einfluss von Emotionen auf Kaufentscheidungen — die neuropsychologische Grundlage hinter Kaufempfehlungen.
- How AI is Revolutionizing Neuromarketing (EN) — die Evolution von EEG-Laboren zu Digital Twins.
Über den Autor: Dr. Jonathan T. Mall ist kognitiver Neuropsychologe und CIO bei neuroflash, wo er Digital-Twin-Technologie für prädiktive Zielgruppenintelligenz entwickelt. Er hält internationale Keynotes zu Neuromarketing, KI-Sichtbarkeit und synthetischer Marktforschung. Kontakt: jonathanmall.com · LinkedIn.