Digital Twins in Market Research: The Complete Guide 2026
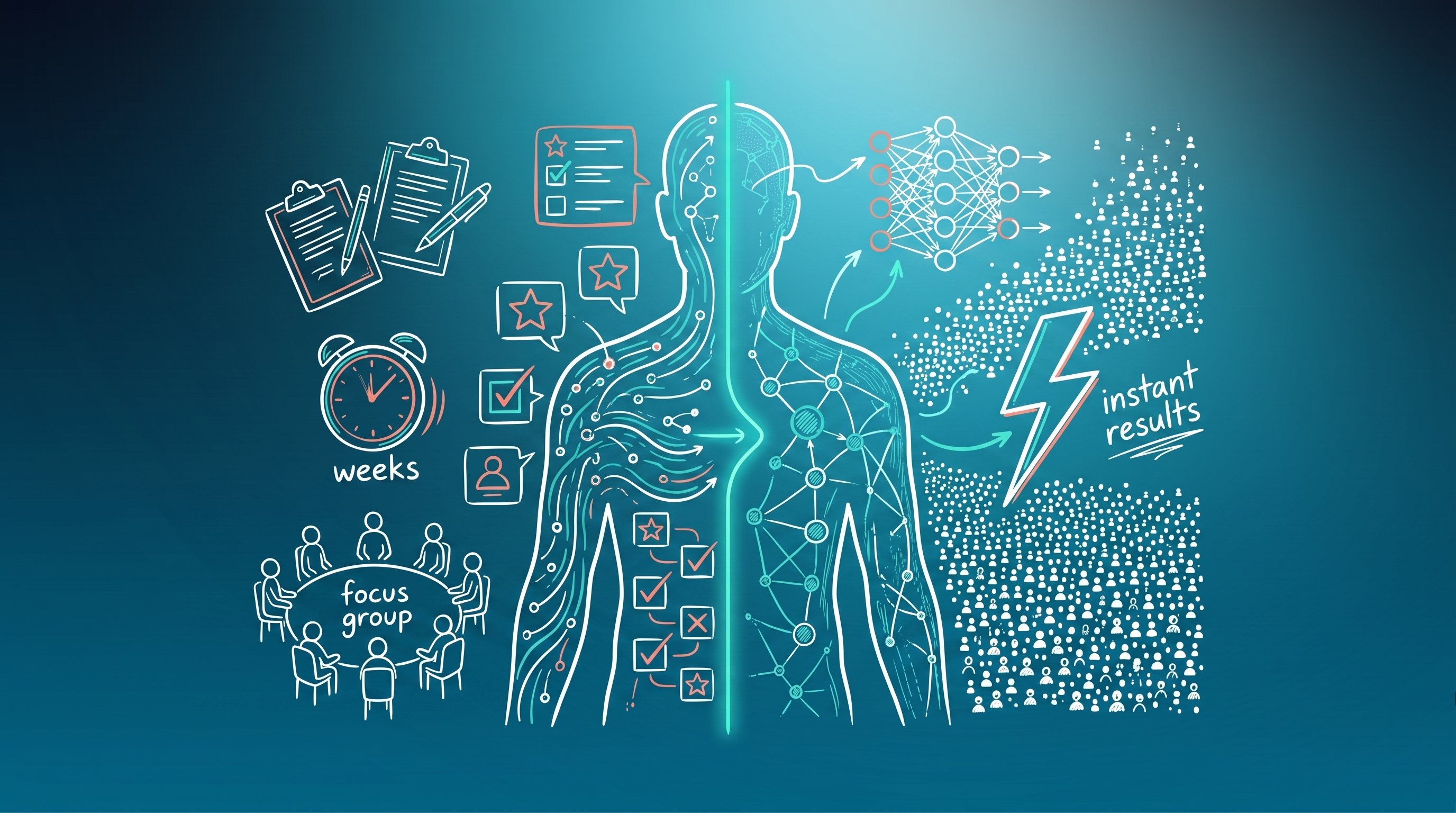
What if you could test your next campaign before spending a single cent on production — no panel booking, no waiting weeks, no arguments about sample sizes that are too small? That’s exactly what Digital Twins promise in market research. And unlike many buzzwords of recent years, this promise is now backed by a growing body of academic studies and real-world validation.
Summary
Digital Twins in market research are AI-powered synthetic audience profiles built on over one million real survey responses, capable of simulating human response behavior with 80–90% accuracy.
- Digital Twins are not chatbots — they are statistically grounded models built on millions of real data points.
- Results come in minutes instead of weeks, at a fraction of the cost of traditional panels.
- Validation studies from Kantar, P&G, and academic institutions show correlations of r = 0.72 to r = 0.98 against real audiences.
- Gartner predicts that 40% of large enterprises will use Digital Twins in their customer insights process by 2027.
- The technology does not fully replace traditional market research — it makes the process faster and cheaper through intelligent screening.
- GDPR and the EU AI Act set specific requirements that practitioners need to understand.
- The smartest approach is hybrid: Digital Twins for screening and concept testing, traditional panels for final validation.
What Are Digital Twins in Market Research?
The term “Digital Twin” originally comes from engineering: in manufacturing, a digital twin is a real-time simulation of a physical machine — a virtual replica that receives sensor data, predicts failures, and enables optimizations before anyone touches the real system.
In market research, the term means something fundamentally different. Here, a Digital Twin is a synthetic persona profile — an AI model that simulates the response behavior, attitudes, and decision patterns of a specific target audience type. Not an avatar, not a chatbot hallucinating on generic training data. Instead, a statistically grounded model built on psychographic data from millions of real survey responses.
The key difference from a simple AI chatbot: a well-constructed Digital Twin is data-grounded. It doesn’t rely on what a language model assumes about “mothers between 35 and 45 in Germany.” It’s based on what that group actually answered in controlled surveys — about values, purchase motivations, brand perception, media consumption, and dozens of other dimensions.
Concretely: a high-quality Digital Twin is built from 68 to 250 psychographic data points per profile — data distilled from over one million real survey responses. That makes it fundamentally different from a prompt like “respond like a typical American suburban parent.”
What Is a Digital Twin of a Customer?
A digital twin of a customer — also called a digital twin of a consumer or of a target audience — is an AI model of a real customer segment, built from survey, CRM, and behavioral data, that answers questions the way that segment would. Unlike a static persona, it is interactive: you ask it to react to concepts, ads, pricing, or packaging before anything goes live, then validate the winning option with a smaller real-world panel.
How Do Digital Twins Work?
The technology behind Digital Twins is more complex than the simple interface suggests. Here is the four-step process that produces a valid synthetic respondent:
Step 1: Data Foundation — 1 Million+ Real Survey Responses
Everything starts with a massive dataset of real surveys. This data is collected through representative panels — with professional quality assurance protocols, outlier correction, and demographic weighting. The raw data forms the empirical foundation on which everything else is built. Without this data foundation, a “Digital Twin” is nothing more than a fancy prompt.
Step 2: Psychographic Profiling — 68 to 250 Data Points
From the raw data, detailed psychographic profiles are created for each target audience segment. These cover values, personality traits (Big Five), purchase motivations, risk tolerance, media affinity, political and social orientations, and category-specific preferences. The more dimensions a profile covers, the more precise the subsequent simulation.
Step 3: Semantic Vector Matching
When a question or stimulus (for example, an ad, a product description, or a claim) is passed to the Digital Twin, the system analyzes semantic similarities between the stimulus and the profile vector. This step — often implemented as Retrieval-Augmented Generation — is what ensures the responses aren’t generic, but consistent with the twin’s specific profile. The mechanisms used are similar to those behind the evolution from simple chatbots to complex AI systems.
Step 4: AI-Driven, Data-Grounded Response Generation
The language model then generates the response — but not freely. It is filtered through the psychographic lens of the profile. The model is instructed to respond consistently with the values, attitudes, and communication style of the profile. Modern implementations use multiple AI agent layers to handle consistency and quality assurance.
Want to see Digital Twins live? In my talk “Digital Twins: The Future of Market Research,” I run a live demo with real data. Request a speaking slot
5 Use Cases for Marketers
1. Pre-Testing Campaigns and Messaging
This is the classic use case — and for good reason. Before a campaign goes into production, you can run different versions of headlines, visuals, tone, and messaging through a Digital Twin. Which messaging resonates with your core audience? Which claim gets misunderstood? Which phrasing triggers a purchase impulse — and which creates unconscious resistance? In practice, this means: a consumer goods company tests 15 variants of a new product claim in two hours, identifies the three strongest, and sends only those into a classic consumer panel for fine-tuning. Time and cost savings: substantial. This approach is especially powerful when you understand how emotions drive purchase decisions — because that’s exactly what a good Digital Twin captures.
2. Audience Analysis Without Surveys
Want to understand how a niche audience — say, sustainability-conscious millennials in mid-sized cities — thinks about your product category? Traditional approach: recruitment, panel fees, field time. With Digital Twins: you query a psychographically matched profile directly. This is ideal for exploratory preliminary analysis, preparing creative briefs, or quickly finding out which segments are even receptive to a topic. One limitation: for niches that are significantly underrepresented in the training data, validity decreases — more on that later.
3. Content Validation Before Publishing
It’s not just ads you can test in advance — blog posts, whitepapers, product pages, and social media content can also be validated. The Digital Twin evaluates readability, emotional impact, and relevance from the perspective of your target audience. Particularly valuable: you can test whether a technical document is understood by non-experts, or whether a LinkedIn article will appeal to the right decision-makers. This saves costly revision rounds after publication.
4. Competitive Analysis from the Customer’s Perspective
How does your target audience perceive your competitor — and where do you come out ahead? Digital Twins make it possible to simulate brand perception from a genuine customer perspective, without expensive tracking studies. You can test how different segments respond to competitor attributes, where your brand is perceived as stronger, and where you need to catch up. This complements classic competitive intelligence research effectively — similar to the approach I took in my analysis of AI visibility across automotive brands.
5. Brand Positioning and Pricing Tests
Pricing is one of the most critical — and expensive — areas of market research. Digital Twins allow you to simulate price sensitivity analyses (Van Westendorp method) and conjoint analyses before recruiting real panels. This isn’t intended as a full replacement, but as an efficient first step: you quickly find out whether your intended pricing model is fundamentally viable or whether you need to rethink the positioning. Brand names, packaging concepts, and product bundles can also be efficiently pre-screened.
Digital Twins vs. Traditional Market Research
Instead of many words, here’s the direct comparison:
| Criterion | Traditional Market Research | Digital Twins |
|---|---|---|
| Speed | 2–6 weeks | Minutes to hours |
| Cost | €10,000–€50,000 | A fraction of that |
| Sample size | 100–1,000 participants | Drawn from 1M+ profiles |
| Repeatability | New recruitment required | Instantly repeatable |
| Accuracy | Gold standard (but expensive) | 80–90% agreement |
| Group dynamics | Susceptible to social bias | No social desirability bias |
| Niche audiences | Hard to recruit | Instantly available |
| Data privacy | Personal data | Synthetic data |
The takeaway from this comparison isn’t “Digital Twins are better.” It’s that these technologies are optimized for different phases of the research process. Traditional market research remains the gold standard for final validation, for deep qualitative insights, and for decisions with regulatory implications. Digital Twins are optimal for the early phases: screening, concept selection, iteration cycles.
What does this mean for your team?
Instead of launching a project with a €30,000 study, you can screen ten concepts in minutes, identify the three strongest, and validate only those with a traditional panel. That saves 70–80% of the budget — with comparable result quality.
Validation: How Accurate Are Digital Twins?
This is the central question — and the honest answer is: it depends. On the quality of the data foundation, on the type of questions, on the target audience segment being tested. Here’s what the research actually shows.
Academic Studies
The scientific foundation for working with synthetic respondents was laid by Argyle et al. (2023) in the landmark study “Out of One, Many” [1]. The authors demonstrated that large language models are capable of replicating the response patterns of different demographic groups on opinion surveys — with remarkable accuracy when models are conditioned with persona profiles. The study is considered the founding work of the field and has been cited hundreds of times since.
Horton (2023) extended this groundwork in a study published in Nature Human Behaviour [2], testing LLMs as simulated economic agents. The conclusion: language models can validly model consumer behavior under the right conditions — but only when grounded in solid empirical data, not when operating on generic training data.
Industry Validation
Kantar published a comprehensive validation study for synthetic respondents in advertising research in 2025 [3]. The results are soberly realistic: ad breakthrough metrics showed a correlation of r = 0.81 with real panels, brand linkage r = 0.72, and purchase intent r = 0.64. Kantar’s own conclusion: synthetic respondents are valid for screening decisions, but do not replace final validation for high-stakes choices.
A study by the University of Mannheim (2024) examined the perception of German automotive brands [4]. The correlation between Digital Twin results and real consumer judgments was r = 0.83 — a strong result demonstrating that the technology works even for the German market with its specific cultural characteristics.
Procter & Gamble presented findings at the 2025 ARF conference (Advertising Research Foundation) [5] from a large-scale pilot program: 85% agreement with real panels on go/no-go decisions for new product campaigns. The company estimated annual savings from synthetic respondents at $12 million USD — with no reduction in decision quality.
Real-World Case Studies
neuroflash has two proprietary validation studies on record [6]: for Oetinger Verlag — detailed in the Oetinger digital twins case study — a 92% match was measured between Digital Twin results and real reader surveys. For Essity (brands: TENA, Tork, Libresse), the agreement was a remarkable 98% — suggesting an exceptionally strong data foundation for the relevant target segments.
Why Does Accuracy Vary?
The range from r = 0.64 to r = 0.98 comes down to three main factors:
- Quality and depth of the data foundation: The more real survey responses available for a segment, the more precise the twin. Well-documented mainstream segments perform better than niche ones.
- Nature of the question: Attitudes and preferences can be simulated more reliably than highly specific behaviors. “Would you buy this product?” is harder than “What do you think of this ad?”
- Cultural specificity: Regional and linguistic nuances must be covered in the data. A twin trained primarily on US data is significantly less valid for European markets.
What Do Gartner, Forrester, and Deloitte Say?
Gartner predicts that by 2027, 40% of large enterprises will use Digital Twins of Customers in their customer insights processes. Source: Gartner, “Predicts 2025: Digital Twins of Customers”, 2024.
Industry analysts rarely agree on anything — but on this topic, the leading research firms show a remarkable convergence.
Gartner predicted in its “Predicts 2025: Digital Twins of Customers” report [7] that by 2027, 40% of large enterprises will have integrated customer Digital Twins into their insights processes. In a separate report on synthetic data generation [8], Gartner estimates that 75% of companies using AI for synthetic data will reduce their time-to-insight by more than 60%.
Forrester [9] goes further, predicting that synthetic respondents will replace or augment 20% of all consumer surveys by 2027 — with particular momentum in advertising pre-testing and concept development.
Deloitte identified “Synthetic Stakeholders” as one of six macroeconomic forces shaping corporate strategy in the coming years in its Tech Trends 2025 report [10]. The message: this is no longer a niche technology — it’s a strategic capability.
McKinsey [11] documents the diffusion curve: 28% of marketing leaders are already experimenting with AI-generated consumer insights — up from just 8% in 2023. Especially relevant for brand AI visibility: those not building this capability today risk becoming invisible tomorrow.
What does this mean for your team?
If Gartner is right, 40% of your competitors will be working with Digital Twins by 2027. The question isn’t whether you’ll adopt this technology — it’s whether you’ll be building real operational experience while your competition is, or only after them. Early adopters gain a structural learning advantage that’s very hard to close later.
Limitations and Risks
I have little patience for technology enthusiasm without substance. So here’s the part that many vendors leave out of their pitch decks.
Where Digital Twins Hit Their Limits
Exploratory, open-ended research: Digital Twins are excellent at responding to known stimuli. They are considerably weaker at generating truly new, unanticipated insights. A real focus group participant can flip an entire research design with an unexpected association or a completely left-field objection. That rarely happens with synthetic respondents.
Entirely new product categories: When there’s no historical data pattern for a concept — for example, because the product category is just emerging — the empirical foundation is missing. The model can only interpolate, not validate. For disruptive innovations, this is a serious problem.
Culturally specific niches: Subcultures, regional specificities, and highly specific communities (dialects, professional groups, religious segments) are often underrepresented in the training data. Results for these groups should be treated with extra skepticism.
The emotional depth of qualitative research: Body language in a focus group, a spontaneous tear during an emotional testimonial, a participant’s hesitant “I’m not sure why, but…” — these are data points that Digital Twins cannot deliver. For research questions where implicit and emotional reactions are decisive, deep qualitative work remains indispensable.
GDPR and the EU AI Act: What You Need to Know
The good news first: synthetic data is fundamentally not personal data under GDPR — because it cannot be traced back to identifiable individuals. This is a significant compliance advantage over classic panel studies with personally identifiable responses.
However: the European Data Protection Board clarified in its Opinion 28/2024 [12] that large language models — even when outputting synthetic data — often fail to achieve genuine anonymization of source data during the training phase. This means: if a vendor uses your data to train their model, standard GDPR rules apply to those input data.
The EU AI Act, fully enforceable from August 2, 2026, imposes heightened transparency and documentation requirements for AI systems in the “high-risk” category. For market research applications, the classification depends on the specific use case. Particularly relevant: transparency obligations for AI-generated outputs — if you use Digital Twin results in decision-making processes, clear internal documentation is advisable.
For reference: ESOMAR‘s market research guidelines are actively evolving to address synthetic respondents.
Ethical Guidelines
ESOMAR has begun developing specific guidelines for the use of synthetic data in market research. The core requirements: transparency about when and how synthetic methods were used, clear quality assurance processes, and no use of synthetic results for decisions where only genuine human consultation would be ethically appropriate.
In practice, this means: reports based on Digital Twin results should be labeled as such. Methodology should be documented and available for disclosure upon request. And for sensitive domains — health, finance, social issues — a higher validation standard applies.
For conference organizers: This topic captivates both marketing and tech audiences. I bring an interactive live demo — your audience tests Digital Twins in real time. Request a talk
FAQ
Do Digital Twins replace traditional market research?
No — and anyone who claims otherwise is selling you something. Digital Twins are a powerful screening and iteration tool that makes the research process faster and cheaper. But for final, high-stakes decisions — product launches, pricing strategies, rebranding — validation with real people remains the gold standard. The smartest use is hybrid: Digital Twins for early phases, traditional panels for final validation. This typically saves 70–80% of the budget with comparable overall decision quality.
How much do Digital Twins cost compared to focus groups?
A classic focus group with 8–10 participants, professional moderation, and analysis typically costs €5,000–€15,000 in Germany or comparable markets — depending on the target audience, location, and scope. For more complex studies across multiple segments, it can easily reach €30,000–€50,000 or more. Digital Twin platforms generally offer subscription models or project-based pricing that, for comparable research questions, lands in the low four-figures to low five-figures — with the added benefit of instant repeatability at no extra cost.
Are Digital Twins GDPR-compliant?
Generally yes — because synthetic data is not personal data under GDPR. But pay attention to how your vendor collected the training data and whether valid consent was obtained for the underlying survey data. Also ask whether your input data (briefing texts, stimuli) will be used for model training. Reputable vendors have transparent answers to these questions and appropriate data processing agreements.
How quickly do Digital Twins deliver results?
This is one of the strongest advantages: a simple query of a predefined profile delivers results in minutes. More complex multi-segment analyses with many stimuli can take a few hours. Compared to traditional panels with 2–6 weeks of field time, this is a fundamental difference — especially when you’re working in agile campaign cycles where two weeks of feedback latency can completely block a project.
Which industries are Digital Twins best suited for?
The strongest evidence so far comes from consumer goods (FMCG), OTC pharma, automotive, financial services, and media/entertainment. Industries with well-documented, stable consumer segments benefit most. It gets harder in very young markets (little historical data), in heavily regulated B2B niches (too few respondents in training data), and for highly localized topics. For B2B market research, there are promising early approaches — but the data foundation here is still considerably thinner than in consumer goods.
References
- Argyle, L. P. et al. (2023): “Out of One, Many: Using Language Models to Simulate Human Samples.” arXiv:2306.15895.
- Horton, J. J. (2023): “Large Language Models as Simulated Economic Agents.” Nature Human Behaviour.
- Kantar (2025): Validation Study — Synthetic Respondents in Advertising Research.
- University of Mannheim (2024): Validation Study — German Automotive Brand Perception.
- P&G / ARF (2025): “Synthetic Panels in Consumer Research.” Advertising Research Foundation Conference.
- neuroflash (2024–2025): Proprietary validation data — Oetinger Verlag, Essity.
- Gartner (2024): “Predicts 2025: Digital Twins of Customers.”
- Gartner (2024): “AI and Synthetic Data — Time-to-Insight Predictions.”
- Forrester (2024): “The Future of Consumer Surveys.”
- Deloitte (2025): “Tech Trends 2025: Synthetic Stakeholders.”
- McKinsey (2024): “The State of AI in Marketing.”
- EDPB (2024): “Opinion 28/2024 on LLMs and Data Anonymization.”
About the author: Dr. Jonathan T. Mall is a cognitive psychologist (PhD, RUG 2013), CIO, and co-founder of neuroflash. He combines 20+ years of experience at the intersection of neuroscience, AI, and marketing. As a keynote speaker, he explains why consumers buy in strange ways — and how AI can predict it, often with the same live-demo format used in this guide; you can book an AI keynote speaker for your own event. Contact: jonathanmall.com · LinkedIn.
Frequently Asked Questions
How accurate are Digital Twins compared to real panels?
Validation studies show 80-90% agreement with human respondents, with correlations as high as r=0.81 in Kantar’s ad metrics and up to 98% agreement in neuroflash cases. They are reliable enough for go/no-go screening, but final decisions should still be validated with a real panel.
Do Digital Twins replace traditional market research?
No. They complement it. Use Digital Twins to screen many concepts in minutes, then validate the strongest ones with a classic panel. This hybrid approach keeps quality high while saving an estimated 70-80% of the budget.
Are Digital Twins GDPR compliant?
Synthetic profiles generally are, since they generate aggregated rather than personal data. You still need to document training-data sourcing transparently and account for the EU AI Act. Treat compliance as a documentation task, not an afterthought.